Thread Pool - A Ruby Antihero
Understanding a fundamental Ruby abstraction for concurrency
One of the fundamental concepts in key Ruby libraries that embrace concurrency is the thread pool.
You can find examples of thread pool implementations in gems like puma, concurrent-ruby, celluloid, pmap, parallel, and ruby-thread.
A thread pool is an abstraction for re-using a limited number of threads to perform concurrent work.
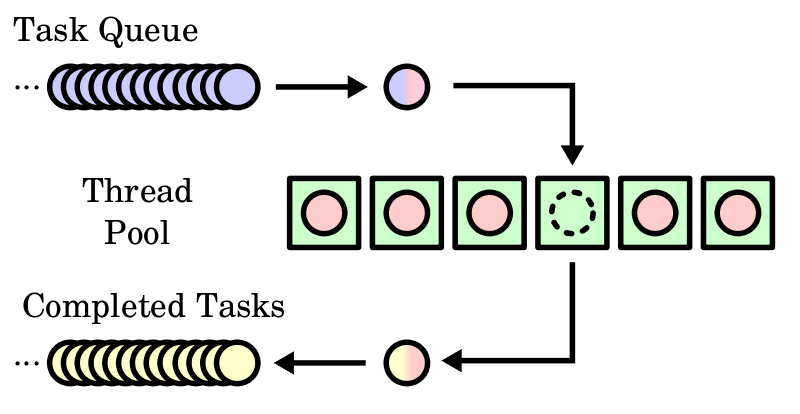
General usage of a thread pool might look something like the following, where the :size
represents the maximum number of threads open at any given time.
pool = ThreadPool.new(size: 5)
10_000.times do
pool.schedule { do_work }
end
pool.shutdown
The calculation would be performed 10,000 times across five separate threads.
To get a better understanding of how thread pools work, let's implement a thread pool in test-driven fashion.
Don't be afraid
Before we dive in, let's acknowledge that Rubyists, and most OO programmers in general, are taught to fear multi-threaded concurrency.
The first rule of concurrency on the JRuby wiki, a Ruby implementation designed to take advantage of native operating systems threads, is this:
Don't do it, if you can avoid it.
For the purpose of this post, I'm going to assume the author means "in production". In the safety of your development environment, playing with concurrency in Ruby can be a tremendous learning opportunity.
A simple thread pool
We'll implement a simple thread pool guided by tests. Our thread pool will use the interface we described earlier while limiting the number of threads used to carry out a set of concurrent "jobs".
pool = ThreadPool.new(size: 5)
pool.schedule { do_work }
pool.shutdown
Basic usage
We'll start with a thread pool that doesn't do any concurrent processing.
It will execute the block given to its #schedule method
directly. Though we'll add other tests later to exercise concurrency in the
implementation, this first test will assume the concurrency is already
implemented.
Here's our first test.
require 'minitest/autorun'
require 'minitest/pride'
require_relative './thread_pool'
class TestThreadPool < Minitest::Test
def test_basic_usage
pool_size = 5
pool = ThreadPool.new(size: pool_size)
mutex = Mutex.new
iterations = pool_size * 3
results = Array.new(iterations)
iterations.times do |i|
pool.schedule do
mutex.synchronize do
results[i] = i + 1
end
end
end
pool.shutdown
assert_equal(1.upto(pool_size * 3).to_a, results)
end
end
Let's break it down. To test the basic usage of a thread pool scheduler, we'll pass in an array and
augment it with in the scheduled blocks. Because Array is not thread safe,
we need to use a Mutex object to lock the pooled threads while adding items to the array.
The key snippet is here:
pool.schedule do
mutex.synchronize do
results[i] = i + 1
end
end
The test asserts that the results match 1.upto(15) as an array.
To make the tests pass:
class ThreadPool
def initialize(size:)
end
def schedule(*args, &block)
block.call(args)
end
def shutdown
end
end
We've just stubbed out the #initialize and #shutdown methods since
additional behavior isn't needed to get the tests to pass.
You can see the source for this changeset on Github.
Saving time
Our next test will demonstrate that we're actually taking advantage of concurrency by (crudely) measuring the time taken to process multiple jobs.
We'll use a small test helper method to measure the number of seconds elapsed during execution:
def time_taken
now = Time.now.to_f
yield
Time.now.to_f - now
end
Our test will schedule 5 jobs that will each sleep for 1 second. If the jobs executed serially, the total execution time would be at least 5 seconds. Running in parallel on Rubinius, we'd expect threaded-execution of 5 jobs across 5 threads to take less time.
def test_time_taken
pool_size = 5
pool = ThreadPool.new(size: pool_size)
elapsed = time_taken do
pool_size.times do
pool.schedule { sleep 1 }
end
pool.shutdown
end
assert_operator 4.5, :>, elapsed,
'Elapsed time was too long: %.1f seconds' % elapsed
end
This test fails with our first pass-through implementation of ThreadPool. We
can make this test pass by wrapping each scheduled job in its own thread.
class ThreadPool
def initialize(size:)
@pool = []
end
def schedule(*args, &block)
@pool << Thread.new { block.call(args) }
end
def shutdown
@pool.map(&:join)
end
end
We push each of these threads onto an array, @pool, which we can use to join
the threads during the #shutdown method. The tests pass again.
Adding Pooling
While we've achieved concurrency, you may notice there's (at least) one problem.
Our current implementation will naively create a new thread for each scheduled job. This may not be an issue for small, trivial use cases, but it can be easily abused. Thread creation does not come for free; every OS has its limit.
We'll prove it with our next test in which we'll schedule a large number of jobs.
def test_pool_size_limit
pool_size = 5
pool = ThreadPool.new(size: pool_size)
mutex = Mutex.new
threads = Set.new
100_000.times do
pool.schedule do
mutex.synchronize do
threads << Thread.current
end
end
end
pool.shutdown
assert_equal(pool_size, threads.size)
end
Running these tests on my mid-2014 MacBook Pro, I hit the resource limit:
TestThreadPool#test_pool_size_limit:
ThreadError: can't create Thread: Resource temporarily unavailable
/Users/ross/dev/rossta/enumerable/examples/thread_pool/thread_pool_test.rb:53:in `initialize'
/Users/ross/dev/rossta/enumerable/examples/thread_pool/thread_pool_test.rb:53:in `new'
/Users/ross/dev/rossta/enumerable/examples/thread_pool/thread_pool_test.rb:53:in `block in test_pool_size_limit'
/Users/ross/dev/rossta/enumerable/examples/thread_pool/thread_pool_test.rb:52:in `times'
/Users/ross/dev/rossta/enumerable/examples/thread_pool/thread_pool_test.rb:52:in `test_pool_size_limit'
This is now the whole point of our ThreadPool, to limit the number of threads
in use. To implement this behavior, instead of executing the scheduled job in a
new thread, we'll add them to a Queue. We'll separately create a
limited number of threads whose responsibility will be to pop new "jobs" off the
queue and execute them when available.
The beauty of Queue is that it is thread-safe; multiple threads in the thread pool can access this resource without corrupting its contents.
Here's the revised implementation:
class ThreadPool
def initialize(size:)
@size = size
@jobs = Queue.new
@pool = Array.new(size) do
Thread.new do
catch(:exit) do
loop do
job, args = @jobs.pop
job.call(*args)
end
end
end
end
end
def schedule(*args, &block)
@jobs << [block, args]
end
def shutdown
@size.times do
schedule { throw :exit }
end
@pool.map(&:join)
end
end
Let's start with the #schedule method. Where before we immediately creating a
new thread to call the block, we instead push the block and arguments onto the
new @jobs queue instance variable.
def schedule(*args, &block)
@jobs << [block, args]
end
This instance variable is setup in the #initialize method where we also
eagerly create the maximum number of threads that will become our worker @pool.
def initialize(size:)
@size = size
@jobs = Queue.new
@pool = Array.new(size) do
Thread.new do
catch(:exit) do
loop do
job, args = @jobs.pop
job.call(*args)
end
end
end
end
end
Each thread runs an infinite loop that repeatedly pops jobs of the queue with
@jobs.pop. The Queue#pop method here will block when the queue is empty so the thread will happily wait for new jobs to be scheduled at this point.
We also use a catch block. We break out of the thread loops by
pushing throw :exit on to the job queue, once for each thread in the
#shutdown method. This means that jobs currently executing when the shutdown
method is called will be able to complete before the threads can be joined.
def shutdown
@size.times do
schedule { throw :exit }
end
@pool.map(&:join)
end
Now we have a simple abstraction for handling concurrent work across a limited number of threads. For more on this implementation, check out the original author's blog post on the subject.
In the Wild
Of course, if you're planning on using a thread pool in production code, you'll be better off leveraging the hard work of others. Our implementation omits some key considerations, like reflection, handling timeouts, dealing with exceptions, and better thread safety. Let's look at some alternatives in the community.
The ruby-thread project provides a few extensions to the standard library Thread class, including Thread::Pool. Usage of Thread::Pool is very similar to what we came up with on the surface.
require 'thread/pool'
pool = Thread.pool(4)
10.times {
pool.process {
sleep 2
puts 'lol'
}
}
pool.shutdown
This implementation goes farther to ensure standard locking functions to work
properly across multiple Ruby implementations. Among other things, it has
support for handling timeouts, methods for introspecting pool objects, like
#running? and #terminated?, and optimizations for dealing with unused
threads. On reading the source, my impression is the implementation was heavily inspired by Puma::ThreadPool, a class used internally by the puma web server. You be the judge.
Celluloid, the most famous
collection of concurrency abstractions, provides a thread pool class,
most commonly accessed via a class method provided by the
Celluloid mixin.
class MyWorker
include Celluloid
def add_one(number)
# roflscale computation goes here
number + 1
end
end
MyWorker.pool
pool.future(:add_one, 5).value
The new hotness for working with concurrency is the toolkit provided by concurrent-ruby. While Celluloid is easy to get started with, Concurrent is the "Swiss Army Knife", providing a large array of abstractions and classes, including futures, promises, thread-safe collections, maybes, and so on. Concurrent provides several different thread pool implementations for different purposes, each supporting a number of configurations, including min and max pool sizes, advanced shutdown behaviors, max queue size (along with a fallback policy when the job queue size is exceeded) to name a few.
pool = Concurrent::FixedThreadPool.new(5) # 5 threads
pool.post do
# some parallel work
end
Consider the Thread Pool overview provided in the Concurrent docs required reading.
And, of course, the ultimate thread pool for Rails developers is Sidekiq. Unlike the examples we've discussed so far, the components of the Sidekiq thread pool model are distributed: the caller, the job queue, and the threaded workers all run in separate processes, often on separate machines, in a production environment.
Credits
In preparing for this post, I read through the source of several thread pool implementations from various sources, ranging from simple examples, to internal interfaces, to public-facing libraries.
- A simple, annotated thread pool
Thread::PoolCelluloid::Group::PoolConcurrent::RubyThreadPoolExecutorPuma::ThreadPool
Though it's well documented how much threads suck, that shouldn't discourage Rubyists from trying to get some first-hand experience with working with threads, supporting classes from the standard library like Queue, Mutex, and ConditionVariable and generic abstractions like ThreadPool.
Connection Pool, the Sequel
Related, though not necessarily thread-based, is the concept of a connection pool, which limits the number of network connections to a particular service. You'll find connection pools in activerecord, mongodb, and, as a standalone abstraction in the approrpriately-named, connection_pool.
It's good to know
about connection pools for setting a connection to Redis from your Ruby
applications with the redis-rb gem. As of this writing, this client does not manage a connection pool for you, so the common gotcha is a memory-leak that originates from creating a lot of open connections to the Redis server. You can avoid this with ConnectionPool:
redis = ConnectionPool.new { Redis.new }
Much like ThreadPool, having at least a cursory understanding of what's happening
underneath can help you avoid issues with managing resources like network
connections.
