Rendering PDF pages with PDF.js and Vue
Building a PDF Viewer with Vue - Part 1
I remember a time not too long ago when the possibility of rendering PDFs inline on a web page would have sounded crazy. Then PDF.js came along and changed all that.
I was recently tasked with just this sort of project, and I leveraged PDF.js, Vue and webpack to put it all together. This post is the first in a series which demonstrates how I used Vue to render PDF pages to <canvas> elements. Later we'll explore conditional rendering and adding paging and zoom controls.
The latest source code for this project is on Github at rossta/vue-pdfjs-demo. To see the version of the project described in this post, check out the part-1-simple-document branch. Finally, here's a link to the project demo.
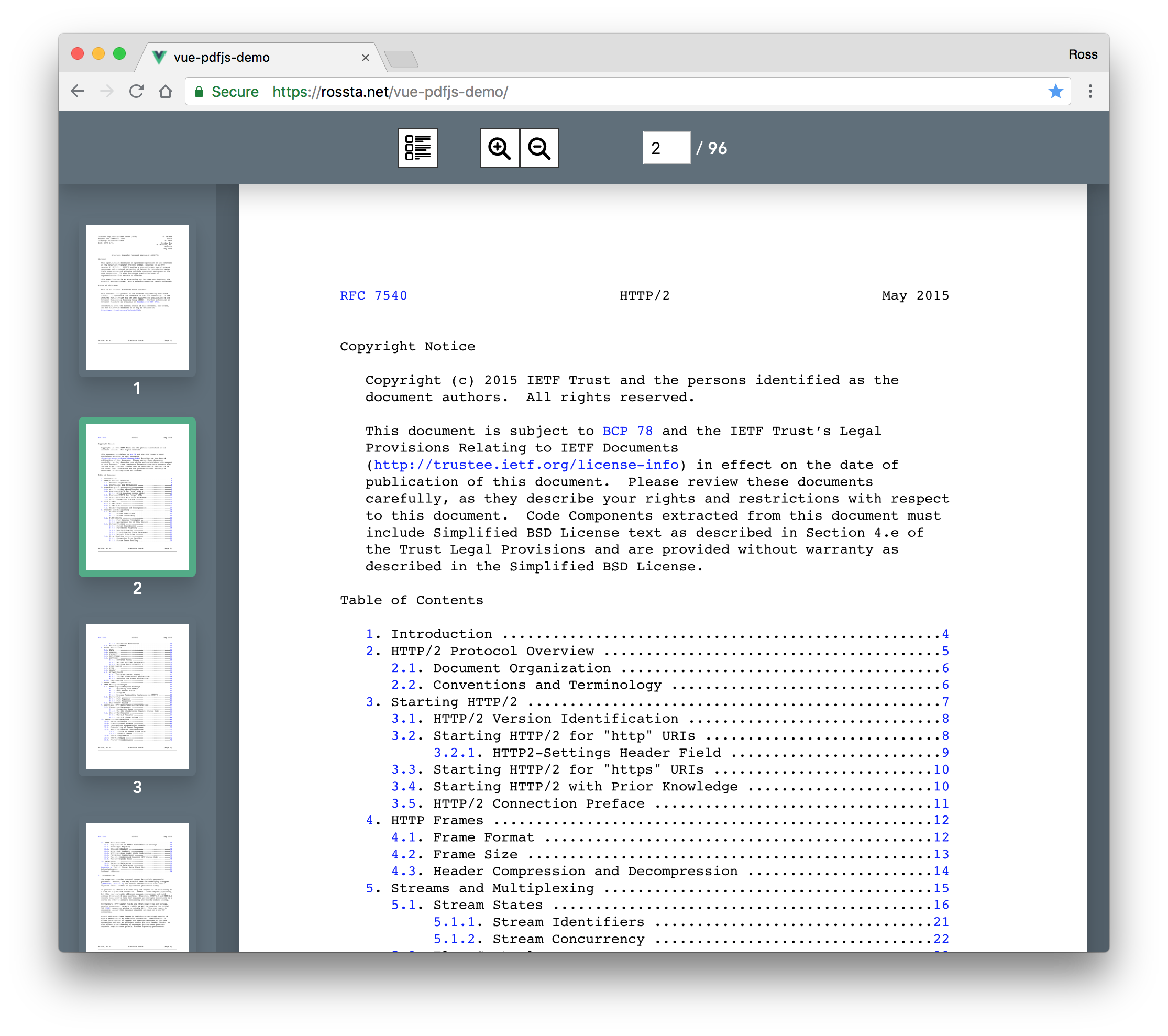
Similar projects
Mozilla's PDF.js package ships with a web viewer (demo) For an alternative approach to PDF rendering with Vue, check out the vue-pdf package.
An incomplete intro to PDF.js
PDF.js is a JavaScript project by Mozilla that makes it easier to parse and render PDFs in HTML. It is comprised of three key pieces: Core, Display, and Viewer.
The Core layer is the lower level piece that parses and interprets PDFs for use by the other layers. This code is split out into a separate file, pdf.worker.js, which will run in a web worker thread in the browser. Since we're using webpack, it handles bundling, fetching, and configuration of the worker script behind the scenes.
The Viewer layer, as I mentioned earlier, provides a primary user interface for viewing and paging through PDFs in Firefox (or other browsers with included extensions). We won't be using this piece; in fact, this tutorial could be used as the basis for a Vue.js implementation of an alternative viewer.
Most of our interaction with the PDF.js library will be at the Display layer, which provides the JavaScript API for retrieving and manipulating PDF document and page data. The API relies heavily on Promises, which we'll be incorporating into our Vue.js components. We'll also take advantage of dynamic imports to code split our use of PDF.js, since, at least for my purposes, I only want to load the PDF.js library on demand. Keeping it out of the main application webpack bundle helps keep the initial page load time small.
Using PDF.js
Here's a basic ES6 example of dynamically loading PDF.js to render an entire PDF document (without Vue):
import range from 'lodash/range'
import('pdfjs-dist/webpack').then(pdfjs => {
pdfjs
.getDocument('wibble.pdf')
.then(pdf => {
const pagePromises = range(1, pdf.numPages).map(number => pdf.getPage(number))
return Promise.all(pagePromises)
})
.then(pages => {
const scale = 2
const canvases = pages.forEach(page => {
const viewport = page.getViewport(scale)
// Prepare canvas using PDF page dimensions
const canvas = document.createElement('canvas')
canvas.height = viewport.height
canvas.width = viewport.width
// Render PDF page into canvas context
const canvasContext = canvas.getContext('2d')
const renderContext = { canvasContext, viewport }
page.render(renderContext).then(() => console.log('Page rendered'))
document.body.appendChild(canvas)
})
},
error => console.log('Error', error),
)
})
The code above dynamically imports the PDF.js distribution with import('pdfjs/dist'). Webpack splits the PDF.js code out into a bundle and loads it asynchronously only when that line is executed in the browser. This expression returns a promise that resolves with the PDF.js module when the bundle is successfully loaded and evaluated. With a reference to the modules, pdfjs we can now exercise the PDF.js document API.
The expression pdjs.getDocument('url-to-pdf') also returns a promise which resolves when the document is loaded and parsed by the PDF.js core layer. This promise resolves to an instance of PDFDocumentProxy, which we can use to retrieve additional data from the PDF document. We used the PDFDocumentProxy#numPages attribute to build a number range of all the pages (using lodash range) and build an array of promises representing requests for each of the pages of the document returned by PDFDocumentProxy#getPage(pageNumber). The key here to loading all pages at once is using Promise.all to resolve when all pages are retrieved as PDFPageProxy objects.
Finally, for each page object, we create a separate canvas element and trigger the PDFPageProxy#render method, which returns another promise and accepts options for a canvas context and viewport. This render method is responsible for drawing the PDF data into the canvas element asynchronously while we append the canvas elements to document.body.
Refactoring to Vue
Our little script works, and for some applications, this may implementation may be sufficient. However, let's say we need some interaction, like paging controls, zoom buttons, conditional page fetching and rendering while scrolling, etc. Adding complexity could get unwieldy quickly. For this next stage, we'll refactor to Vue components, so we can get the benefit of reactivity and make our code more declarative and more natural to extend.
In pseudocode, our component architecture resembles this:
<PDFDocument>
<PDFPage :number="1" />
<PDFPage :number="2" />
<PDFPage :number="3" />
...
</PDFDocument>
Requirements
For my project, I used the following npm packages (installed using yarn).
@vue/cli:^3.0.0-beta.15vue:^2.5.16pdfjs-dist:^2.0.489
I would expect it to be straightforward to adapt the code for other relatively recent versions of these packages.
Fetching the PDF
Our <App> component hard-codes default values for a PDF url and a rendering scale. A <PDFDocument> child component receives this data as props.
<!-- src/App.vue -->
<template>
<div id="app">
<PDFDocument v-bind="{url, scale}" />
</div>
</template>
<script>
export default {
// ...
data() {
return {
url: 'https://cdn.filestackcontent.com/5qOCEpKzQldoRsVatUPS', // a PDF
scale: 2,
}
},
}
</script>
The document component is responsible for fetching the PDF data through PDF.js and rendering a <PDFPage> component for each page object returned by the API.
Its data will track the pdf object and a list of page object in pages.
// src/components/PDFDocument.vue
export default {
props: ['url', 'scale'],
data() {
return {
pdf: undefined,
pages: [],
};
},
// ...
When the component is mounted, it will fetch the PDF data using the pdfjs.getDocument function.
// src/components/PDFDocument.vue
export default {
//...
created() {
this.fetchPDF();
},
methods: {
fetchPDF() {
import('pdfjs-dist/webpack').
then(pdfjs => pdfjs.getDocument(this.url)).
then(pdf => (this.pdf = pdf));
},
},
//...
We'll use a watch callback for the pdf attribute to fetch all the pages via the pdf.getPage function provided by PDF.js. Since the return value of getPage behaves like a promise, we can use Promise.all to determine when all the page objects have been fetched and set the resolved collection as the pages data:
// src/components/PDFDocument.vue
import range from 'lodash/range';
export default {
// ...
watch: {
pdf(pdf) {
this.pages = [];
const promises = range(1, pdf.numPages).
map(number => pdf.getPage(number));
Promise.all(promises).
then(pages => (this.pages = pages));
},
},
};
The template simply renders a <PDFPage> child component for each page object. Each page component also needs the scale prop for rendering the page data to <canvas>:
<!-- src/components/PDFDocument.vue -->
<template>
<div class="pdf-document">
<PDFPage
v-for="page in pages"
v-bind="{page, scale}"
:key="page.pageNumber"
/>
</div>
</template>
Setting up the canvas
Now we can build out the <PDFPage> element. We'll use a Vue render function to create a <canvas> element with computed attributes, canvasAttrs.
// src/components/PDFPage.vue
export default {
props: ['page', 'scale'],
render(h) {
const {canvasAttrs: attrs} = this;
return h('canvas', {attrs});
},
// ...
To render a PDF to <canvas> with an acceptable resolution, we can take advantage of a browser property called window.devicePixelRatio. This value represents the ratio of screen pixels to CSS pixels. Given a hi-resolution display with a devicePixelRatio of 2, we'd want to give the canvas initial width and height attributes that are two times greater than its corresponding width and height in CSS. Otherwise, rendering our PDF pixels to canvas may appear blurry.
When the <PDFPage> component is created, we can access the viewport property of the page object, via PDFPageProxy#getViewport, to obtain the pixel width and height of the PDF. These are the width and height attributes of the <canvas> element. For the actual size of the <canvas>, we'll use CSS attributes.
Since the scale prop is reactive and our render function depends on canvasAttrs, defining canvasAttrs as a computed property based off the scale means our PDF pages automatically re-render when the scale changes. Future iterations allow changes to the scale prop (using future zoom controls, for example). We'll calculate the width and height via CSS to update the rendered size of the canvas to avoid redrawing the canvas data from the page object each time. For this, we use a clone of the original viewport, given via the actualSizeViewport computed property, and the devicePixelRatio to calculate the target width and height style attributes for the <canvas>.
Here's the code that puts all that together:
// src/components/PDFPage.vue
export default {
created() {
// PDFPageProxy#getViewport
// https://mozilla.github.io/pdf.js/api/draft/PDFPageProxy.html
this.viewport = this.page.getViewport(this.scale);
},
computed: {
canvasAttrs() {
let {width, height} = this.viewport;
[width, height] = [width, height].map(dim => Math.ceil(dim));
const style = this.canvasStyle;
return {
width,
height,
style,
class: 'pdf-page',
};
},
canvasStyle() {
const {width: actualSizeWidth, height: actualSizeHeight} = this.actualSizeViewport;
const pixelRatio = window.devicePixelRatio || 1;
const [pixelWidth, pixelHeight] = [actualSizeWidth, actualSizeHeight]
.map(dim => Math.ceil(dim / pixelRatio));
return `width: ${pixelWidth}px; height: ${pixelHeight}px;`
},
actualSizeViewport() {
return this.viewport.clone({scale: this.scale});
},
//...
},
// ...
Rendering the page
When the <canvas> element mounts, we can draw the PDF page data to it using the PDFPageProxy#render method. It needs context from the viewport and canvasContext as arguments. Since that returns a promise, we can be notified when it's complete.
// src/components/PDFPage.vue
export default {
mounted() {
this.drawPage();
},
methods: {
drawPage() {
if (this.renderTask) return;
const {viewport} = this;
const canvasContext = this.$el.getContext('2d');
const renderContext = {canvasContext, viewport};
// PDFPageProxy#render
// https://mozilla.github.io/pdf.js/api/draft/PDFPageProxy.html
this.renderTask = this.page.render(renderContext);
this.renderTask.
then(() => this.$emit('rendered', this.page));
},
// ...
},
// ...
Cleaning up after ourselves
As we're working with JavaScript objects that keep state outside of Vue's control, we should be mindful of calling provided teardown methods. The PDF document and page objects provide destroy methods to be called on teardown, such as, when our render promise fails, the page object is replaced, or the Vue component itself is destroyed.
// src/components/PDFPage.vue
export default {
beforeDestroy() {
this.destroyPage(this.page);
},
methods: {
drawPage() {
// ...
this.renderTask.
then(/* */).
catch(this.destroyRenderTask);
},
destroyPage(page) {
if (!page) return;
// PDFPageProxy#_destroy
// https://mozilla.github.io/pdf.js/api/draft/PDFPageProxy.html
page._destroy();
// RenderTask#cancel
// https://mozilla.github.io/pdf.js/api/draft/RenderTask.html
if (this.renderTask) this.renderTask.cancel();
},
destroyRenderTask() {
if (!this.renderTask) return;
// RenderTask#cancel
// https://mozilla.github.io/pdf.js/api/draft/RenderTask.html
this.renderTask.cancel();
delete this.renderTask;
},
},
watch: {
page(page, oldPage) {
this.destroyPage(oldPage);
},
},
};
Wrapping up
We've now converted our original, imperative PDF rendering script with a declarative Vue component hierarchy. We've certainly added much code to make this work, but with a working knowledge of Vue, we've made it easier to reason about, easier to extend, and easier to add features to give our PDF viewer more functionality.
In the next post, we'll look at adding some conditional rendering; since all pages aren't visible when the document is initially loaded, Vue can help us design a system that only fetches and renders PDF pages when scrolled into view.